One-shot
公司门禁用了人脸识别,你只提供一张照片,门禁就能认识各个角度的你,这就是 one-shot。可以把 one-shot 理解为用 1 条数据 finetune 模型。
Zero-shot
即,利用已有的数据和知识,来推理辨认模型从没见过的数据,也就是“0条没见过的数据”
例子:
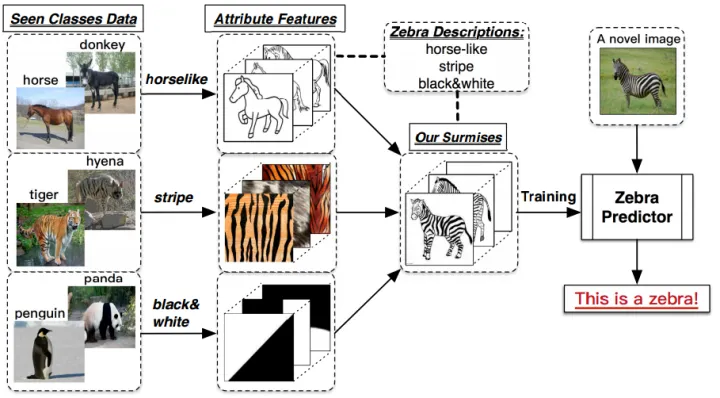
小明和爸爸,到了动物园,看到了马,然后爸爸告诉他,这就是马;之后,又看到了老虎,告诉他:“看,这种身上有条纹的动物就是老虎。”;最后,又带他去看了熊猫,对他说:“你看这熊猫是黑白色的。”然后,爸爸给小明安排了一个任务,让他在动物园里找一种他从没见过的动物,叫斑马,并告诉了小明有关于斑马的信息:“斑马有着马的轮廓,身上有像老虎一样的条纹,而且它像熊猫一样是黑白色的。”最后,小明根据爸爸的提示,在动物园里找到了斑马
定义:
- 有训练集数据$X_{tr}$及其标签$Y_{tr}$,包含了模型需要学习的类别(马、老虎、熊猫)
- 有测试集数据$X_{te}$及其标签$Y_{te}$,包含了模型需要识别的类别(斑马)
- 有训练集数据和测试集数据的描述$A_{tr},A_{te}$,将每个类别$y_i \in Y$,都表示成一个语义向量$a_i \in A$的形式,这个向量的每个维度都是一个具体的属性,例如有嘴巴,有尾巴,有眼睛…,当这个类包含这个属性时,该维度的值设为非零值
- 希望使用$X_{tr},A_{tr}和Y_{tr}$来训练模型,然后希望模型能够根据$A_{te}$来识别$X_{te}$,就是Zero-shot的目的
方法:
- 将图片数据$X$通过GoogleNet等模型提取图片特征数据,称之为特征空间
- 将类别的语义化表示$A$,称为语义空间
- 需要做的就是将特征空间映射到语义空间,或者将语义空间映射到特征空间,例如使用岭回归的方法
- 将$x_i \in X_{te}$特征空间映射到语义空间后,计算离它最近的$a_i \in A_{te}$,则该样本对应的标签即为$a_i$所对应的标签$y_i$
Few-shot
few-shot即是因为Zero-shot的效果不尽人意,因此人为地标注了少量(few)优质数据加入训练以提高模型准确率。
零次学习(Zero-Shot Learning)入门 (zhihu.com) 数据集案例Describing Objects by their Attributes (uiuc.edu)
 2024
2024